


Software Performance Optimization Toolbox
A box of solutions for your performance issues


Last time we discussed how to design test plans to uncover performance issues (software-performance-troubleshooting-and-optimization).
In this article, we are going to systematically discuss the types of bottlenecks and what options we have to solve them.
Resource
The most common bottlenecks are resource limits. If you observed that the CPU, RAM, or Network utilization reach its limit, adding more resources to the system has a high possibility to solve your issue, temporarily. This solution is easy to understand. Be cautious, more costs can surely ease the current pressure of the system, however in most cases spending more money on resources just means buying our system more time to fix them. A deep diagnosis of the system is needed to solve them.
| Resource Type | Solution | Potential Issue |
| CPU & RAM | Use a better machine with a better CPU and bigger RAM or use more replicas. | Higher cost. And depending on the type of new CPU, your system may face some incompatibility issues. |
| Disk | local SSD > local disk > remote storage. Assign more disk space and use a better disk with a higher I/O speed. Set an alert when space is almost full. | Changing the storage type may involve a data migration. It's a dangerous step and needs a concise plan when migrating. Compatibility and consistency need to be considered at the same time. |
| Network | Increase the network bandwidth. Change the network plan. Use a better ethernet card with a faster speed. | Consider the network bottlenecks in all spots on the process chain like the load balancer, gateway, and centralized services. |
Algorithms & Reuse Resource
The algorithm is the hottest topic when talking about performance. Different process logic results in totally different process times. There are a lot of websites that hold discussions that talk about the best and the quickest approach to algorithms. We are not going to discuss specific algorithms here. But discuss the best approaches when we code and the thoughts behind them.
Allocate Memory Beforehand
Using a pre-allocated array instead of a zero-sized array can save a lot of memory allocation time when processing a big volume of data.
func ListLoop(pCycle interface{}) {
cycle := pCycle.(int64)
l := make([]int64, 0, 0)
for i := int64(0); i < cycle; i++ {
l = append(l, i)
}
return
}
func ListLoopWithSize(pCycle interface{}) {
cycle := pCycle.(int64)
l := make([]int64, 0, cycle)
for i := int64(0); i < cycle; i++ {
l = append(l, i)
}
return
}
func MapLoop(pCycle interface{}) {
cycle := pCycle.(int64)
m := make(map[int64]bool)
for i := int64(0); i < cycle; i++ {
m[i] = true
}
return
}
func MapLoopWithSize(pCycle interface{}) {
cycle := pCycle.(int64)
m := make(map[int64]bool, cycle)
for i := int64(0); i < cycle; i++ {
m[i] = true
}
return
}
Here are 4 functions that do the same thing using 4 different data structures: list, pre-allocated list, map, and pre-allocated map. By running these functions by passing 10,000,000 as input, we get the followings:
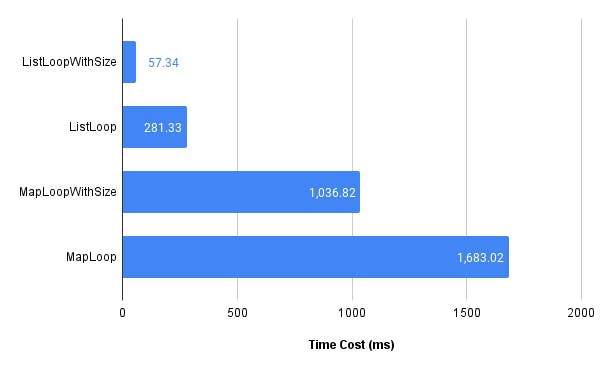
For lists, a pre-allocated list iterates a lot faster than a zero-sized list. The same conclusion can be applied to maps too. What happened under the hood is that as the list grows, the original fixed-sized array needs to be replaced by a bigger array to hold more items. So a memory allocation and copy happened when keep appending items into the list.
The reason pre-allocated lists and maps are fast is that the under-layer memory slot is reused and not recreated.
Reuse Resource Instead of Creating New
In OOD (Object Oriented Design), we often define a lot of controller objects to hold data and methods. Creating and Initializing steps of the controller instances are often lengthy and complicated. When coding, we often want to reuse these instances to save the initialization cost.
One common pattern is to use the Single Instance. (Not singleton. Singleton is hard to be unit tested, hard to control the dependencies, and could hide a lot of issues.)
| Pattern | Pros | Cons |
| Single Instance | 1. Reuse instances by saving the initialization and recycling cost. | 1. One instance is used by all dependencies, implementation needs to consider the data segregation to prevent concurrent errors. |
| 2. Globally ensure one controller instance is used in the application. | 2. Some controllers are not stateless. The state management needs to be carefully designed. | |
| Singleton | All of the above and 1. Is easy to be overused and results in a tightly coupled and hard-to-maintain state code. | |
| 2. Potential memory leak as the singleton instance can persist in memory even after the program has finished running. |
At the code level, dependency injection is a good solution to solve the problems caused by over usage of the singleton pattern. There are a lot of coding techniques worth diving deep into. But we are going to focus back on our topic.
As we mentioned above, reusing instances can save re-creating costs. But by sharing one instance across the whole application the bottleneck of this single instance can be easily reached. For example, the database client holds one connection to the database. If in one second, the application has 100 requests to the database. All 100 requests have to go through this one connection to transport.
Here an object pool pattern can be applied to solve this issue.
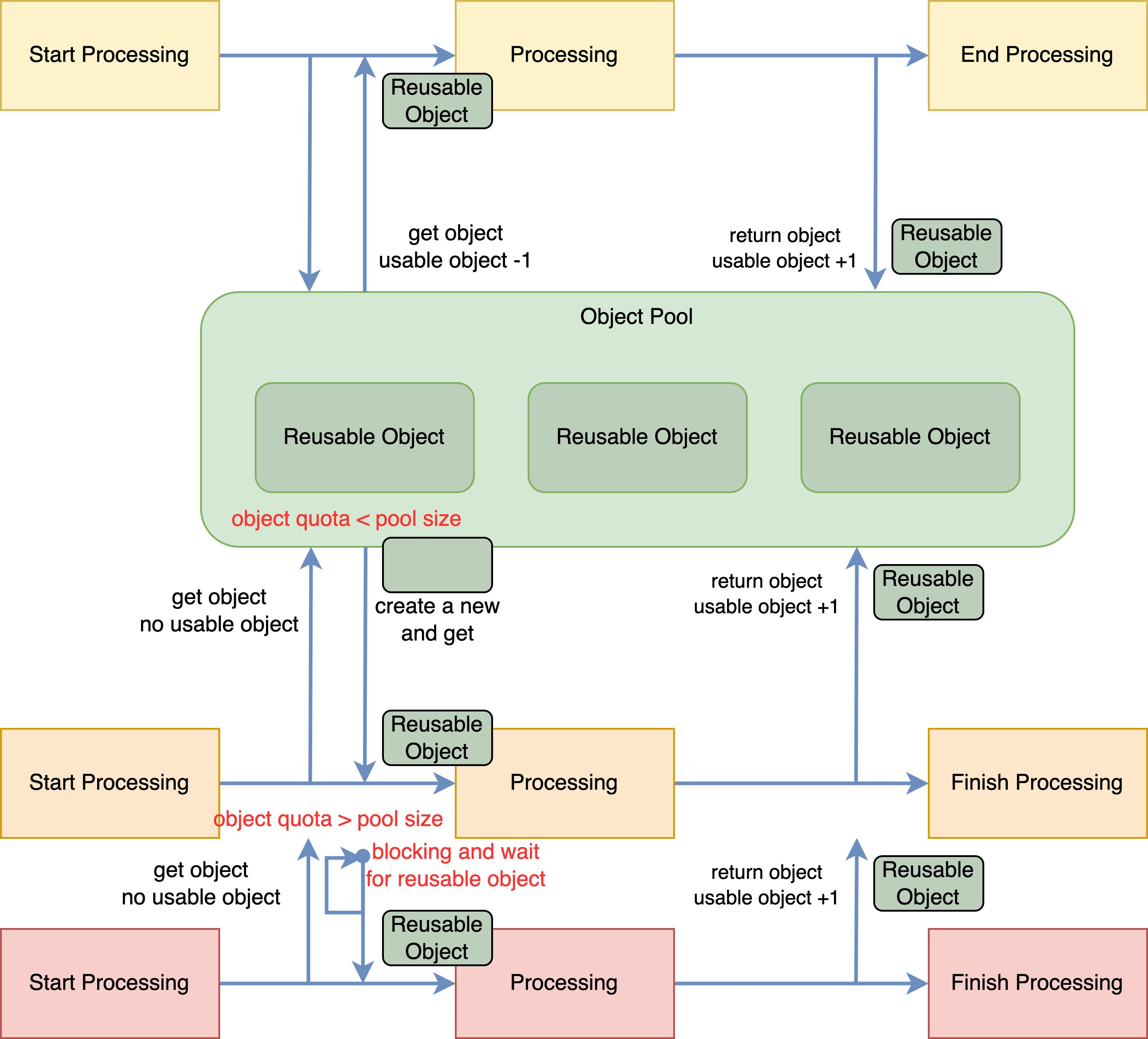
The pool size controls the max number of objects in the application. When the number of object requests is bigger than the number of created objects and smaller than the size of the pool, a new object will be created to be added to the reuse cycle. And if the need for the object is larger than the size of the pool and the recycling can not fulfill the need of use, the request will be blocked. In this case, the pool plays the role of a request limiter to protect the application.
By dynamically maintaining the size of the pool and the number of instances in the pool, we can get to the balancing point of resource reusing and re-creating.
Return Early When Throwing Error
Error handling is tedious but important. For the service that accepts the public request, input validation and error checking are more important than others. When processing a load of data, detecting the error earlier will help the system to abandon the invalid requests earlier and save more resources for the valid ones.
One quick example is database queries. By examing the SQL statement before sending the request to the database, the errors like column names can be detected. This saves at least a round-trip time.
Multi-thread Over Single-thread
Using multithread can surely improve the performance of your service. But it comes with some issues that need to be considered during the implementation:
| Type | Issues | Solutions |
| Thread Explosion | More threads do not equal better performance as the context switching between threads also counts. | Use thread pool to limit the max number of threads that can be created to make the best use and reuse threads. |
| Data Consistency | When one set of data is split into chunks to be processed by different threads, each thread will generate one set of results. It's inevitable to get conflicts when merging the results into one. | From an algorithm perspective, designing the data structure to avoid overlapping is one way out. From an infrastructure perspective, separating the data processing logic and result merging logic can prevent modifying the same object from happening. |
Lazy Loading
It is important that loading resources as fast as possible to shorten the initialization process. But due to some extra constraints like bandwidth and signal strength of edge devices, the loading process could take longer than it supposes to. When one-time loading is costly and slow, lazy loading comes into place.
Basically, lazy loading means that loads resources only before the resources are used. Web pages use this technic a lot to reduce open time. The webpage is split into several parts. When the user opens the webpage, only the first few parts are loaded. As the scroll bar moves, the rest loads as needed.
The backend server also uses it to reduce start-up time and save memory. Assume you have a component in the service that is rarely called. And every time the component loading process costs 10 seconds. Lazy loading for this component is a perfect choice as the component is loaded as needed and can be released after it is used.
But there is a couple of downsides to the lazy loading. As the component that uses lazy loading need to be initialized to be used, the request needs to wait for the initialization to finish to get served. This often refers to a cold start problem. Another issue is that lazy loading is hard to test and verify. The issue is revealed only after the component is loaded and initialized. A specific request is required to trigger this.
Data Consistency - Lock
To support high concurrency, locking is one main solution to maintain data consistency. Locking the object makes it relatively easy to change parallel operations into sequential operations.
Locking techniques can be roughly grouped as the followings:
Thread Lock: Synchronize operations locally in the thread level
Distributed Lock: Synchronizes operations across the distributed system
Optimistic Locking: Assumes that multiple transactions can frequently complete without interfering with each other. Using techniques like version number, data conflict can be found and a retry will be triggered to ensure data consistency.
Pessimistic Locking: Acquire the lock every time before executing operations and release the lock after. Only the operator that has the lock has permission to edit the data.
But be careful to use the lock as deadlock problems are hard to troubleshoot. Also if the lock is used too broadly, the system will be blocked by all kinds of locks and the lock itself will become the biggest bottleneck.
Data Fetching - Database & Cache
The Data layer is an essential part of the system. Different databases serve different purposes but they may all face performance bottlenecks as data size grows and the business model becomes complex.
How to optimize a database?
This question is answered thousands of times already. We are not going to go deep into it here. But the general thoughts are the followings:
Add indexing to speed up data searching
Use a better algorithm or SQL to query
Simplify data models
Use replicas to increase throughput
Use sharding to split datasets and diverge requests
However, if the high concurrency is normal and slow response is damaging the business, a cache needs to be used to boost the service as the database I/O has limits.
The Cache can be divided into two main categories based on implementations:
Local Cache
The cache lives on the local computer. The software service can access the cache without any network requests.
In Memory Cache
| Pros | Cons |
| 1. Superfast. | 1. Memory is expensive and small. It can't hold too much data. An OOM error could be easily triggered as data explodes. |
| 2. Easy to implement and use. | 2. A eviction policy needs to be designed to protect service from OOM which adds complexity to the system. |
| 3. Data will be lost if the service restarts. | |
| 4. GC will be longer than usual if the cache dumped a lot of data at once. |
Disk Cache
| Pros | Cons |
| 1. Big and cheap | 1. Depending on the storage type, I/O could slow. |
| 2. New volumes can be easily mounted to expand raised limit or no upper limit if using cloud storage. | 2. The storage-full could block the server OS from running |
| 3. Ensure data persistency | 3. In addition to the eviction policy to manage the valid data, a data clean-up policy need to be implemented to delete files from the disk as well. |
Indeed local cache is fast, however, when the hosts are many, the data synchronization could also burden the database.
Given a system serves a massive amount of clients and one service has 1000 replicas. Each replica holds an in-memory cache with an expiration time. Requests are evenly distributed among 1000 hosts. Thus if one record is added, to synchronize this new record, at least 1000 queries will be requested to the database. The same to other database operations. So in this case, a remote cache can be used.
Remote Cache
Separated from local service and computer, a remote caching service like Redis can be used. Connected by an internal network, the caching service can be utilized with a small network overhead.
| Pros | Cons |
| 1. Easy to use and config | 1. Expensive |
| 2. High availability and high stability are ensured. | 2. Need dedicated people to maintain the service |
Issues With Cache
By using a cache, the need for reading and writing data can be fulfilled under high concurrency. However, data replication, data eviction, and hotspot data could cause issues.
| Issues | Root Cause | Solutions |
| Data Inconsistency | 2 copies of data in both cache and database. The data in the database is updated but the cache is not or vice versa. | Lock or atomic data syncing policy |
| Cache Avalanche | Cache keys are evicted at the same time or the cache service is down or restarted. Also, a cold start system could face this issue too. | Use random expiration time for cache keys or add replicas to cache service to ensure high availability |
| Cache Penetration | The request to data that exists neither in the cache nor in the database, the query will search in both places before returning. This would occur under malicious attacks. | Use a rate limiter or make the request sequential to block massive requests to databases at the same time. Put not-exist data into the cache as well to block further queries to databases. |
| Hotspot Dataset Failure | Only one layer of cache is used. A hotkey is expired and massive requests for this hotkey are coming to the service. | Use more than one layer of cache with different expirations. Use a rate limiter before questing the database to protect it. Make the requests to the same key sequential. |
How To Design Cache Logic?
Define the type of cache: Read Only VS Read & Write
Define the level of Consistency: Final Consistency VS Strong Consistency
Define the type of data synchronization: Synchronous VS Asynchronous
Based on the above, design your caching logic with your business need.
Add more details as needed.
Gate of Services - Network
For web services, network bottlenecks are issues with bandwidth and time costs. The bigger the bandwidth, the higher the cost. To reduce the cost and speed up the performance, we could optimize our connection strategies and data exchange protocols.
Data To Exchange
When we pass data from one side to another through the internet, the data size and the number of requests are big factors in transport time.
Compression
if you find your request is sending hundreds of KB every time, compress first before sending it may save you a lot of bandwidth.
But the downside is that compression consumes computing resources which may increase CPU utilization. Also, the other side needs to decompress your request body to process it. Thus an examination needs to be done to compare the computing cost and the bandwidth cost. This is a classic situation that uses computing to save time. Different compression algorithms are also contributing.
Use Batch Instead
In a micro-service system, data exchanges between services are normal. In the early stage of the business, services request single resources every time it is needed.
However, when the system grows to be more data-intensive, resources could be queried more than a hundred times per second. In this case, implementing a cache on the client side could be a solution to reduce the data retrieving cost. But if totally different data is requested every time, adding a cache is definitely the wrong choice.
One solution is to merge single data requests into batches to save the network overhead. Instead of sending 100 requests for 100 resources, using one batch to read them all could save you a lot of network time.
The classic case to apply this optimization is the item loading page for the web store. When the first page contains all the hottest items to sell, you want to get them all once the recommending system gives the list as opposed to loading them one by one.
Server-client connection
A client often wants to get the latest data from the server right after it is updated. There are many ways to realize it, iterative client polling, long polling, web socket, and server-side event.
| Implementation | Pro | Con |
| Iterative Client Polling | Reliable. As long as the client is working, the client can initiate the request to retrieve the updated data in real time. | Waste bandwidth. The request is fired even when the data is not changed. And the performance is highly dependent on the interval of the polling. |
| Long Polling | The long connection can return as soon as the data is changed. Easy to implement as it's just a slow-returned HTTP request. | Since long polling is an unreturned HTTP connection, it has bottlenecks as connections are limited. Also, holding too many unreturned HTTP connections may slow down the server. |
| Web Socket | Bi-directional transportation. Real-time connection. High efficiency as no extra headers after the initial connection. | Hard to implement as it's a low-level implementation. Need to reestablish the connection manually. |
| Server-Side Event | The server side pushed messages to update clients in real-time. The event-based implementation makes that the server side is lightly coupled to the client side. Reconnect automatically after the connection is lost. | Mono-directional connection. Limited concurrent connections. |
Infrastructure - Design Patterns
A good infrastructure could minimize the traffic inside the system and distribute load across the whole system instead of centralizing them in one spot.
Asynchronous
If a backend server is subject to intermittent heavy loads, it could become unstable and reliability issues may raise. Any synchronous call to the service will be affected by the instability and return failed response. To solve this, an asynchronous infrastructure can be applied.
Asynchronous Request-Reply Pattern
The asynchronous Request-Reply pattern returns the response as soon as the server accepts the request. It utilizes a state service to maintain the status and results of the asynchronous tasks. An HTTP looping can be held between the client and server to ensure that the response will be returned once the asynchronous task is processed.
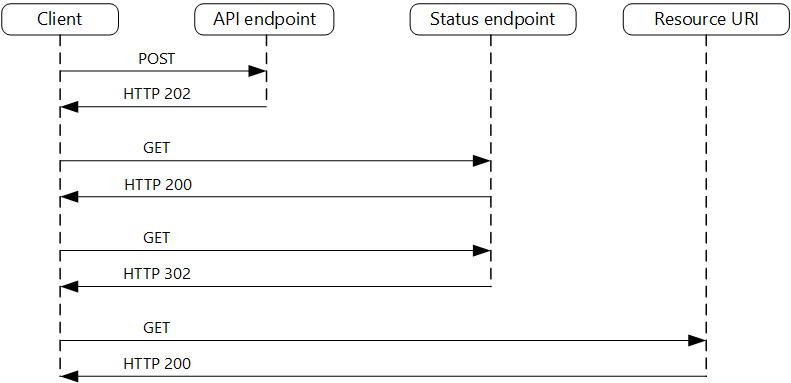
The following diagram shows a typical flow:
The client sends a request and receives an HTTP 202 (Accepted) response.
The client sends an HTTP GET request to the status endpoint. The work is still pending, so this call returns HTTP 200.
At some point, the work is complete and the status endpoint returns 302 (Found) redirecting to the resource.
The client fetches the resource at the specified URL.
In general, this approach split the monolithic service into several lightly coupled blocks.
Request Receiver - Accepts the requests, initiates async tasks
Async-task Processor - The business logic to process the task
Status Maintainer - Maintain the status of the async tasks. Report task status when it's initialized, processing, failed, or succeeded.
Result Holder - Keep and give the results of the processed tasks.
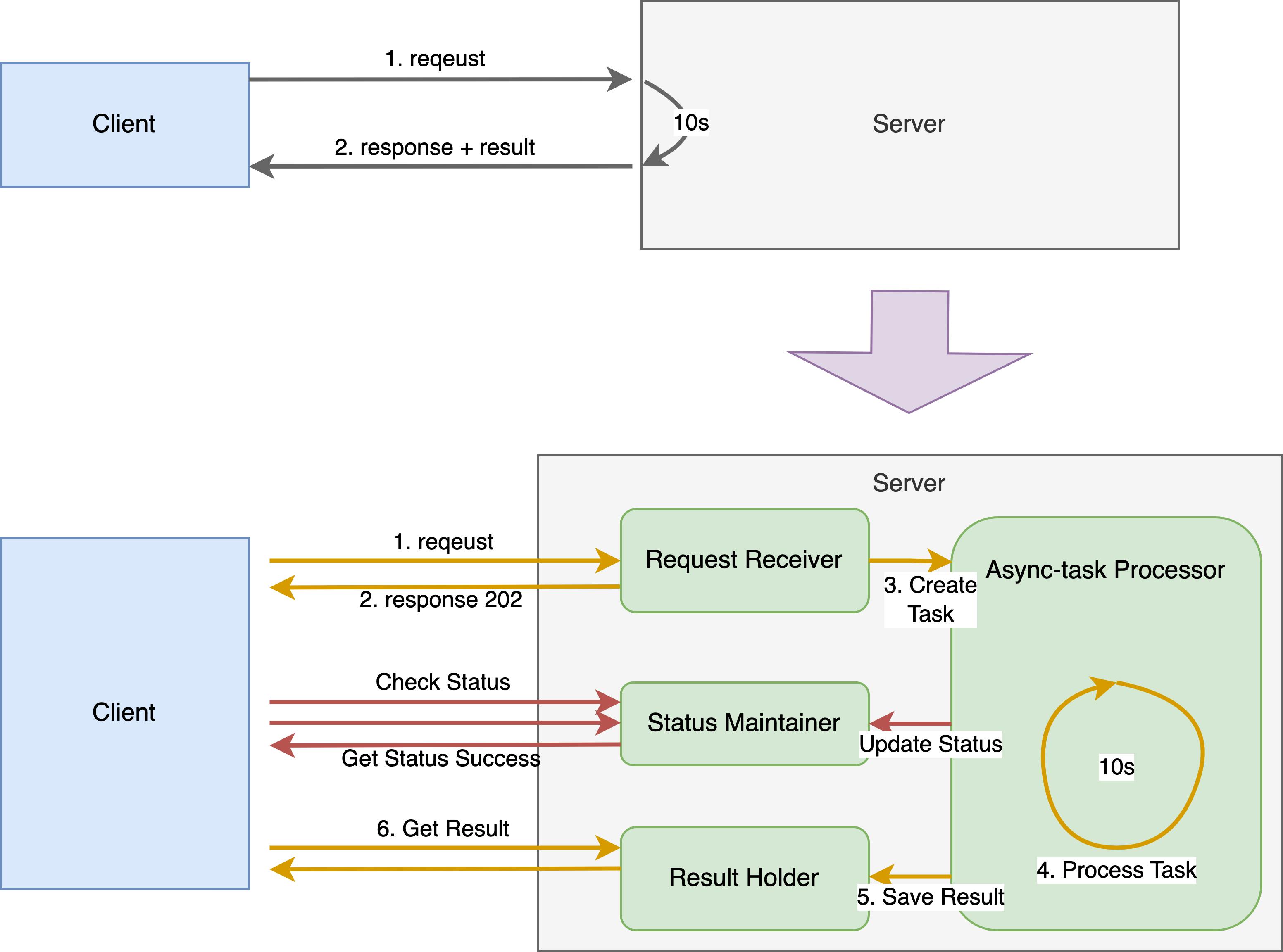
This approach trades the system complexity for stability and resilience. Other than that, some issues also are introduced and need to be taken care of:
The server needs to return 202 once the request is processed. But the client needs to consume the 202 response and send another request to a new endpoint to check for task status. This semantic needs to be implemented correctly by both sides.
Upon error, the error details need to be persisted to inform the client for further retry. To prevent the client from endless status checking in case of error, both the client and server need to implement the timeout strategy to handle this.
The client might want to cancel the previous task to update with a new one. Or the long-running task could fall into an infinite loop. A cancel endpoint needs to be implemented to enable the client to terminate the task.
Queue-Based Load Leveling Pattern
Unexpected intermittent heavy loads could bring down the server as the server is likely to be overloaded. The queue-based load leveling pattern uses a message queue to decouple the two to protect the server from crashes.
.png)
Here the message queue plays the role of the middle layer to hold the request temporarily to allow the servers to consume the requests in a steady fashion. Once the server processed the message, the queue can drop it. The benefits are clear and straightforward. The issues are obvious too:
It is necessary to implement application logic that controls the rate at which services handle messages to avoid overwhelming the target resource. Avoid passing spikes in demand to the next stage of the system. Test the system under load to ensure that it provides the required leveling, and adjust the number of queues and the number of service instances that handle messages to achieve this.
Message queues are a one-way communication mechanism. If a task expects a reply from a service, it may be necessary to implement a mechanism that the service can use to send a response. For more information, see the Asynchronous Messaging Primer.
You must be careful if you apply autoscaling to services that are listening for requests on the queue because this may result in increased contention for any resources that these services share, and diminish the effectiveness of using the queue to level the load.
Summary
Based on the types of performance bottlenecks, we offered various kinds of solutions. But more details need to be considered and filled in by the developer when implementing to solve every and each specific problem. With the considerations of the cost of the fix, the timeline of your product, the urgency, team preference, and the infrastructure of the system, the optimization can be done correctly by every patient, attentive, and bold developer.